Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document Parsing
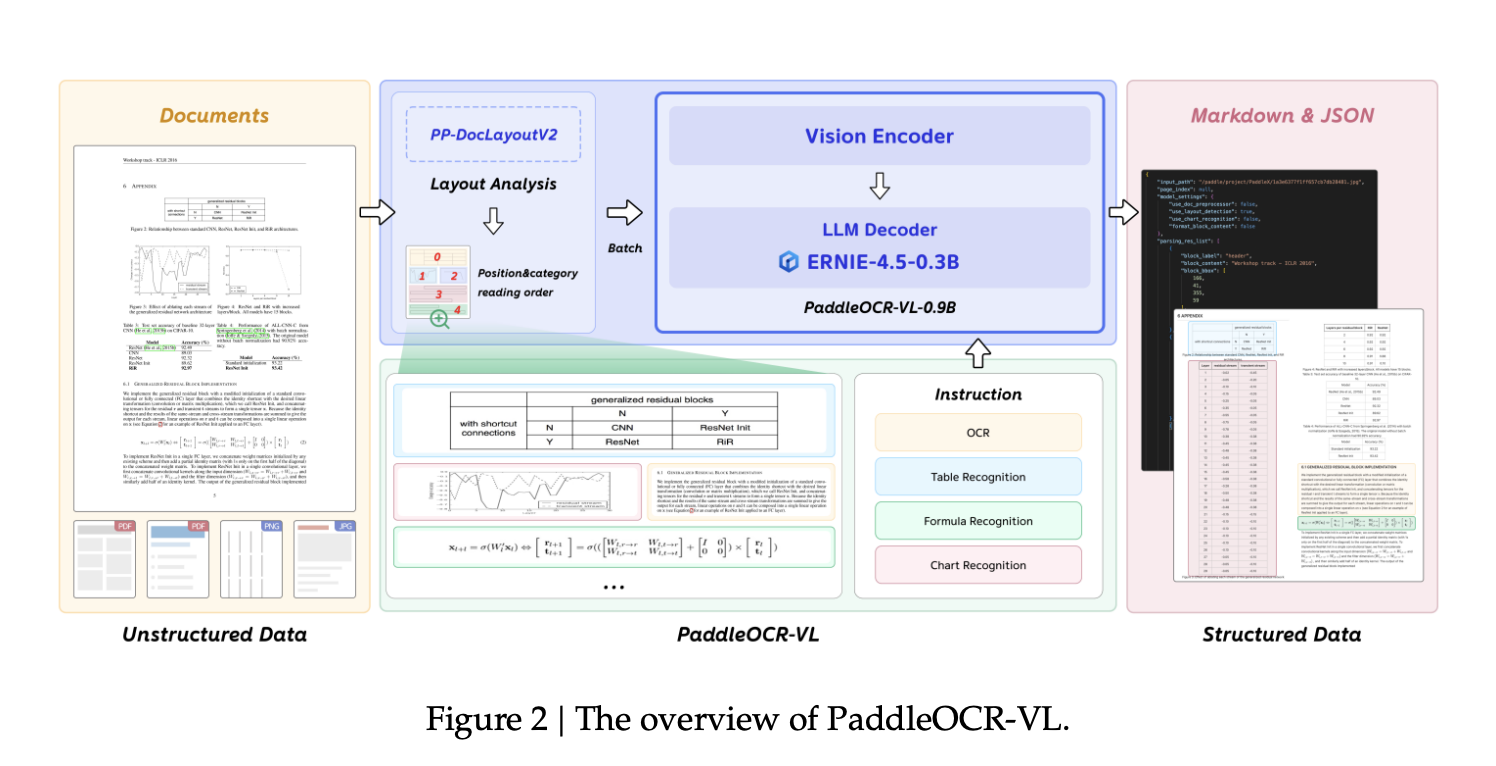

How do you convert complex, multilingual documents—dense layouts, small scripts, formulas, charts, and handwriting—into faithful structured Markdown/JSON with state-of-the-art accuracy while keeping inference latency and memory low enough for real deployments?Baidu’s PaddlePaddle group has released PaddleOCR-VL, a 0.9B-parameter vision-language model designed for end-to-end document parsing across text, tables, formulas, charts, and handwriting. The core model combines a NaViT-style (Native-resolution ViT) dynamic-resolution vision encoder with the ERNIE-4.5-0.3B decoder. It supports 109 languages.

Understanding the system design
PaddleOCR-VL is deployed as a two-stage pipeline. Stage one (PP-DocLayoutV2) performs page-level layout analysis: an RT-DETR detector localizes and classifies regions; a pointer network predicts reading order. Stage two (PaddleOCR-VL-0.9B) conducts element-level recognition conditioned on the detected layout. Final outputs are aggregated to Markdown and JSON for downstream consumption. This decoupling mitigates long-sequence decoding latency and instability that end-to-end VLMs face on dense, multi-column, mixed text–graphic pages.
At the model level, PaddleOCR-VL-0.9B integrates a NaViT-style dynamic high-resolution encoder (native-resolution sequence packing) with a 2-layer MLP projector and the ERNIE-4.5-0.3B language model; 3D-RoPE is used for positional representation. The technical report attributes lower hallucinations and better text-dense performance to native-resolution processing relative to fixed-resize or tiling approaches. The NaViT idea—patch-and-pack variable-resolution inputs without destructive resizing—originates from prior work showing improved efficiency and robustness; PaddleOCR-VL adopts this encoder style directly.
Benchmarks
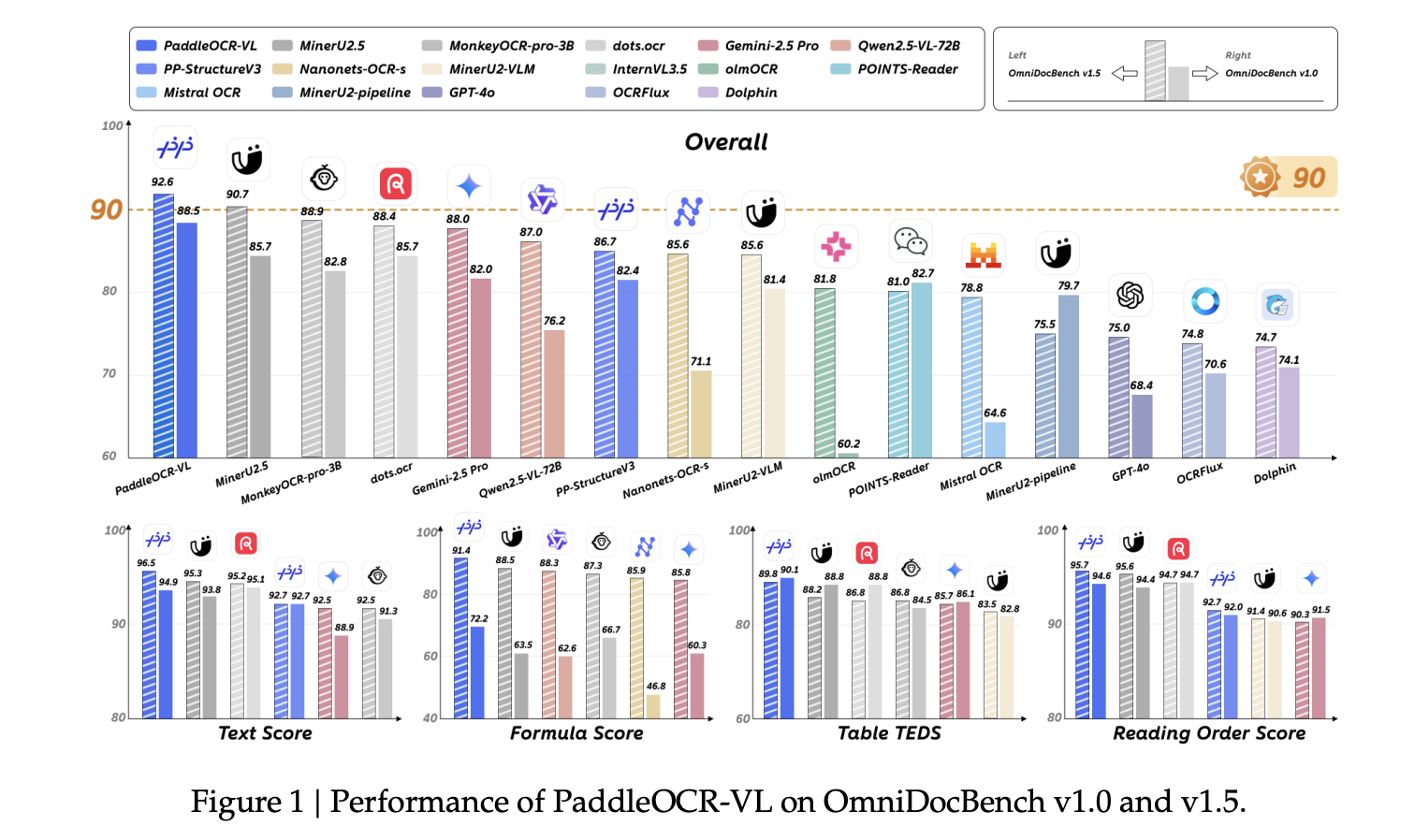
PaddleOCR-VL achieves state-of-the-art results on OmniDocBench v1.5 and competitive or leading scores on v1.0, covering overall quality as well as sub-tasks (text edit distances, Formula-CDM, Table-TEDS/TEDS-S, and reading-order edit), with complementary strength on olmOCR-Bench and in-house handwriting, table, formula, and chart evaluations.

Key Takeaways
- 0.9B-parameter PaddleOCR-VL integrates a NaViT-style dynamic-resolution encoder with ERNIE-4.5-0.3B for document parsing.
- Targets end-to-end extraction across text, tables, formulas, charts, and handwriting with structured Markdown/JSON outputs.
- Claims SOTA performance on public document benchmarks with fast inference suitable for deployment.
- Supports 109 languages, including small scripts and complex page layouts.
Editorial Comments
This release is meaningful because it joins a NaViT-style dynamic-resolution visual encoder with the lightweight ERNIE-4.5-0.3B decoder to deliver SOTA page-level document parsing and element-level recognition at practical inference cost. The two-stage PP-DocLayoutV2 → PaddleOCR-VL-0.9B design stabilizes reading order and preserves native typography cues, which matter for small scripts, formulas, charts, and handwriting across 109 languages. Structured Markdown/JSON outputs and optional vLLM/SGLang acceleration make the system operationally clean for production document intelligence.
Check out the Technical Paper, Model on HF, and Technical details . Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document Parsing appeared first on MarkTechPost.
