Closing the ‘Expressivity Gap’: How Mistral’s Voxtral TTS is Redefining Multilingual Voice Cloning with a Hybrid Autoregressive and Flow-Matching Architecture

Voice AI has a dirty secret. Most text-to-speech systems sound fine — until they don’t. They can read a sentence. What they cannot do is mean it. The rhythm is off. The emotion is flat. The speaker sounds like themselves for two seconds, then drifts into generic synthetic territory. That gap between intelligible audio and truly expressive, speaker-faithful speech is what we call the ‘Expressivity Gap’ — and it has been the defining bottleneck for every developer trying to build production voice agents, audiobook pipelines, or multilingual customer support systems that actually hold up under human scrutiny.
Mistral AI’s new release, Voxtral TTS, is a direct attempt to close that gap. It is Mistral’s first text-to-speech model, released simultaneously as open weights on Hugging Face and as an API, and it makes a bold architectural bet: use two completely different modeling paradigms — autoregressive generation and flow-matching — for the two completely different problems that voice cloning actually involves.

The result is a model totaling approximately 4B parameters — a 3.4B decoder backbone, a 390M flow-matching acoustic transformer, and a 300M neural audio codec — that generates natural, speaker-faithful speech in 9 languages from as little as 3 seconds of reference audio, achieves a 68.4% win rate over ElevenLabs Flash v2.5 in multilingual voice cloning evaluations conducted by native speaker annotators, and serves over 30 concurrent users from a single NVIDIA H200 at sub-600ms latency.
The Expressivity Gap: Why One Model Can’t Do It All
Think of speech as two completely separate signals traveling in the same waveform. There is the semantic layer — the words, the grammar, the linguistic structure. And there is the acoustic layer — the identity of the speaker, their emotional register, their prosody and rhythm.
These two layers have fundamentally different statistical properties, and forcing a single modeling approach to handle both of them simultaneously forces a painful compromise. Autoregressive models are great at long-range consistency — keeping a speaker sounding like themselves across a full paragraph — but they are slow and expensive when applied to the 36 acoustic codebook tokens that define fine-grained audio texture per frame. Flow-based models are exceptional at generating rich, continuous acoustic variation, but they lack the sequential memory that makes a speaker sound coherent over time.
The Voxtral TTS Architecture: Two Jobs, Two Models
Voxtral TTS is built around three components that work together in a single end-to-end pipeline.
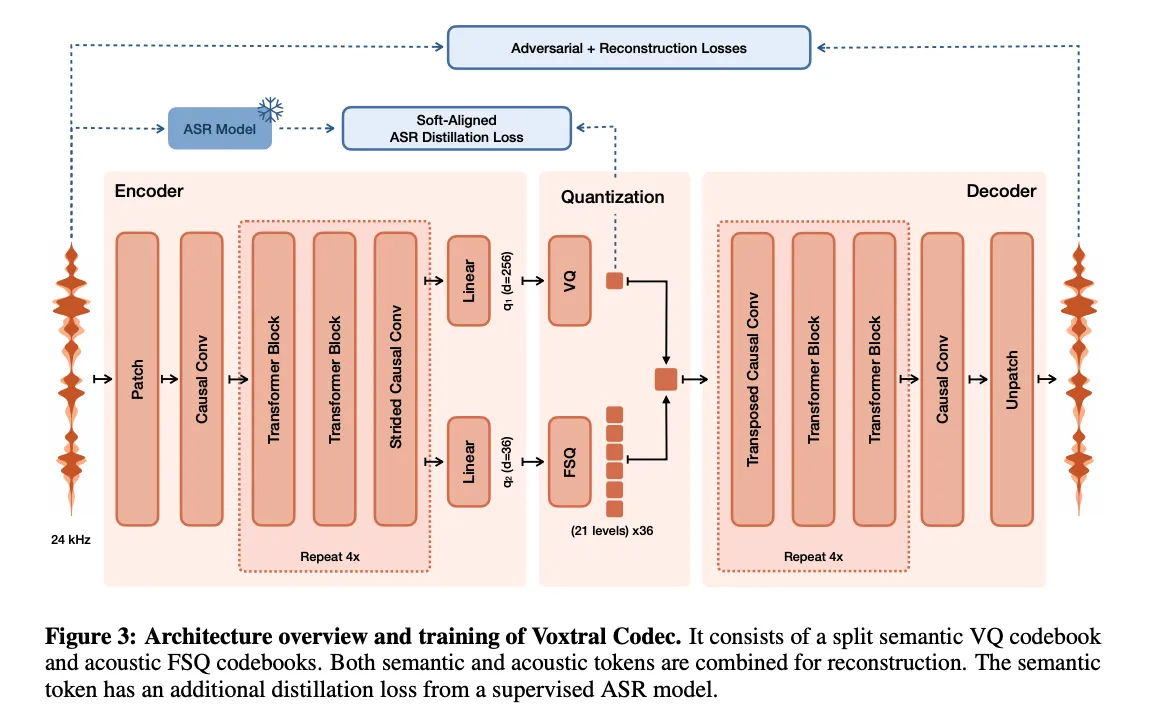
1. Voxtral Codec — The Audio Tokenizer
- The Structure: A custom convolutional-transformer autoencoder trained from scratch with a hybrid VQ-FSQ quantization scheme.
- How It Works: Takes a raw 24 kHz mono waveform and compresses it into 12.5 Hz frames — one frame per 80ms of audio. Each frame becomes 37 discrete tokens: 1 semantic token (using Vector Quantization with a codebook of 8,192 entries) and 36 acoustic tokens (using Finite Scalar Quantization at 21 levels per dimension). Total bitrate: ~2.14 kbps. The semantic token is trained using a frozen Whisper ASR model as a distillation target, so it learns text-aligned representations without needing any external forced aligner.
- Best For: Compressing voice references for downstream generation and decoding generated tokens back to waveform.
- Why: Compared to Mimi (the codec in Moshi) at similar bitrates, Voxtral Codec outperforms on Mel distance, STFT distance, PESQ, ESTOI, ASR word error rate, and speaker similarity on the Expresso benchmark.
2. Autoregressive Decoder Backbone — The Semantic Engine
- The Structure: A decoder-only transformer initialized from Ministral 3B, with audio tokens prepended to text tokens as context.
- How It Works: The voice reference (3–30 seconds) is encoded into audio tokens by Voxtral Codec and placed at the start of the input sequence. The text to be spoken follows. The decoder autoregressively generates one semantic token per frame — one per 80ms — until it produces a special <EOA> (End of Audio) token. A linear head maps the decoder’s hidden states to logits over the 8,192-entry semantic vocabulary.
- Best For: Maintaining long-range speaker consistency and adapting to the identity established in the voice reference.
- Why: This is the part of the system that ensures the speaker sounds like themselves from the first word to the last. Autoregressive generation excels at exactly this kind of sequential coherence.

3. Flow-Matching Transformer — The Acoustic Engine
- The Structure: A bidirectional 3-layer transformer that models acoustic tokens in continuous space using flow-matching with classifier-free guidance (CFG).
- How It Works: At each generation step, the hidden state from the decoder backbone is passed to the FM transformer. Starting from Gaussian noise, the transformer runs 8 function evaluations (NFEs) using the Euler method, with a CFG scale of α = 1.2, to produce the 36 acoustic token values for that frame. The float values are then discretized to 21 FSQ levels before the next AR decoding step.
- Best For: Generating the fine-grained acoustic texture — speaker timbre, expressivity, emotional coloring — that makes synthesized speech sound alive rather than robotic.
- Why: The ablation in the research paper compared flow-matching against MaskGIT and a Depth Transformer for acoustic prediction. Flow-matching won on expressivity in human evaluations and is also computationally superior: a Depth Transformer requires 36 autoregressive decoding steps per frame; the FM transformer needs only 8 NFEs.
Post-Training: How DPO Makes the Model Less Robotic
After pretraining on paired audio and transcripts, Voxtral TTS is post-trained using Direct Preference Optimization (DPO). Because the acoustic tokens use flow-matching rather than a standard discrete head, the research team adapted a flow-based DPO objective alongside the standard DPO loss for the semantic codebook.
Winner-loser sample pairs are constructed using word error rate (WER), speaker similarity scores, loudness consistency, UTMOS-v2, and LM judge metrics. The key finding: training for more than one epoch on synthetic DPO data makes the model sound more robotic — not less. One epoch is the sweet spot.
The payoff is measurable. German WER drops from 4.08% to 0.83%. French WER drops from 5.01% to 3.22%. UTMOS scores improve across all nine languages. The model hallucinates less, skips fewer words, and no longer tapers in volume across long utterances. The one caveat: Hindi WER regresses slightly with DPO (3.39% → 4.99%) — the research team flag it explicitly, and it is the only language where word error rate moves in the wrong direction.

The Full Competitive Picture: Where Voxtral Wins
The human evaluation results deserve a more complete reading than the headline win rate alone.
In zero-shot voice cloning (the model’s clear strength), Voxtral TTS beats ElevenLabs Flash v2.5 at 68.4% overall — and the gap widens further when you look at speaker similarity on automated benchmarks. On SEED-TTS, Voxtral scores 0.628 speaker similarity versus 0.392 for ElevenLabs v3 and 0.413 for ElevenLabs Flash v2.5.
In flagship voice evaluations with implicit emotion steering (the model infers emotion from the text without any tags), Voxtral TTS beats both ElevenLabs models: 55.4% over v3 and 58.3% over Flash v2.5.
Gemini 2.5 Flash TTS currently holds a lead in Explicit Emotion Steering (following direct text commands like “speak angrily”), this reflects its nature as a general-purpose instruction-following model rather than a specialized audio engine. In contrast, Voxtral TTS prioritizes Acoustic Authenticity. Voxtral TTS wins 37.1% of the time against Gemini in implicit emotion steering. It achieves emotional resonance by leveraging a reference voice that naturally embodies the requested register.
The distinction is clear: while Gemini is an excellent ‘actor’ following a script, Voxtral TTS is the more ‘authentic’ voice, making it the superior tool for applications where speaker similarity and natural human cadence are the primary requirements.
Cross-Lingual Voice Adaptation
Voxtral TTS also demonstrates zero-shot cross-lingual voice adaptation, even though it was not explicitly trained for this capability. You can provide a French voice prompt with English text, and the resulting speech is natural English with the accent of the French speaker. This makes the model immediately useful for cascaded speech-to-speech translation pipelines without any additional fine-tuning.
Use Case Studies: Where Voxtral TTS Actually Shines
Use Case 1: The Multilingual Voice Agent
- The Goal: A customer support platform that handles calls in Arabic, Hindi, Spanish, and English using a single consistent brand voice, adapted per language from a 10-second reference clip.
- The Problem: Most TTS systems perform well in English but degrade significantly in low-resource languages. Maintaining speaker identity across languages is nearly impossible without per-language fine-tuning.
- The Solution: Deploy Voxtral TTS via the Mistral API at $0.016 per 1,000 characters. Provide a short reference clip once; the model handles all nine languages. Zero per-language fine-tuning required.
- The Result: In blind human evaluations, Voxtral TTS achieved a 79.8% win rate over ElevenLabs Flash v2.5 in Hindi and 87.8% in Spanish. Arabic win rate: 72.9%. The expressivity gap closes hardest in exactly the languages where competitors struggle most.
Use Case 2: The Real-Time Audiobook Pipeline
- The Goal: Generate narrator-faithful audiobook audio at scale from manuscript text, preserving the user’s specific voice and emotional range across hours of content.
- The Problem: Long-form generation requires temporal coherence across thousands of frames. Most systems start drifting in speaker identity well before the end of a chapter.
- The Solution: Run Voxtral TTS via vLLM-Omni on a single NVIDIA H200. The autoregressive decoder backbone maintains long-range consistency across the full generation sequence. The flow-matching transformer handles per-frame acoustic expressivity — ensuring that an excited sentence actually sounds excited, inferred from the text itself without any emotion tags.
- The Result: A single H200 serves this workload at 1,430 characters per second at concurrency 32, with a real-time factor (RTF) of 0.302 and zero audio chunk wait rate. The model generates up to two minutes of audio natively.
Use Case 3: The Zero-Shot Voice Cloning Developer
- The Goal: Build a product that lets users clone any voice from a short recording and use it for personal voice assistant, accessibility tools, or content creation — without requiring studio-quality audio.
- The Problem: Most voice cloning systems require 30+ seconds of high-quality reference audio and degrade badly on in-the-wild recordings (background noise, variable microphone quality, conversational speech patterns).
- The Solution: Voxtral TTS works on voice references as short as 3 seconds and performs best on prompts between 3 and 25 seconds — explicitly designed for real-world, not studio, audio. Serve it with the open weights on any GPU with ≥16GB VRAM using vLLM-Omni.
- The Result: In zero-shot voice cloning human evaluations across 9 languages and 60 text prompts, Voxtral TTS was preferred over ElevenLabs Flash v2.5 in 68.4% of instances — significantly wider than the 58.3% win rate on flagship preset-voice comparisons. The model is better at generalizing to new voices than to its own trained defaults.
Ready to Start?
Mistral AI has made Voxtral TTS accessible through two paths depending on your use case:
- For API access: Available now in Mistral Studio at $0.016 per 1,000 characters with 20 preset voices including American, British, and French dialect options. Output is 24 kHz audio in WAV, PCM, FLAC, MP3, AAC, or Opus format. No infrastructure required.
- For self-hosted deployment: The open weights are available at mistralai/Voxtral-4B-TTS-2603 on Hugging Face under CC BY-NC 4.0. The model runs on a single GPU with ≥16GB VRAM via vLLM-Omni (v0.18.0+).
Check out the research paper and the Mistral blog post for the full technical details on architecture, training, and benchmark methodology.
Note: Thanks to the Mistral AI team for supporting us for this article.
The post Closing the ‘Expressivity Gap’: How Mistral’s Voxtral TTS is Redefining Multilingual Voice Cloning with a Hybrid Autoregressive and Flow-Matching Architecture appeared first on MarkTechPost.
